TF-IDF Term Fequency - 指搜尋關鍵字在該文件中的出現頻率(詞頻)。 Inverse Document Frequency - 由於某些詞的使用非常普遍而在文件中不斷的出現(比如英文文章中的”the”),這可能使該詞的權重變高,但它可能不是一個重要的搜尋關鍵字,因此使用IDF來計算該詞在所有文件中的出現頻率,如果在所有文件中,該詞頻仍然很高,那麼它與文件的關聯性被認為是較低的,因此會透過得出的值去減少該詞的權重。
answer = 'y' while (answer == 'y'): term = input('Search (enter a term to query): ') ranking = engine.search(term) print("Displaying results for " + "'" + term + "':") if ranking isNone: print(' No results :(') else: rank = 1 for doc in ranking: print(' ' + str(rank) + '. ' + doc) rank += 1 print() answer = '' whilenot (answer == 'y'or answer == 'n'): answer = input('Would you like to search another term (y/n) ')
for line in self.file: for word in line.split(): word = re.sub(r'\W+', '', word) self.term_list.append(word.casefold())
for word in self.term_list: num_of_words = len(self.term_list) if word notin self.term_dict: self.term_dict[word] = 1 / num_of_words else: self.term_dict[word] = (self.term_dict[word] * num_of_words + 1) / num_of_words
defget_path(self): return self.filepath
defterm_frequency(self, key): key = re.sub(r'\W+', '', key) key = key.casefold() result = self.term_dict.get(key) if result isNone: return0 return result
import math import os import re from document import Document
classSearchEngine: def__init__(self, directory): self.__allDocs = [] self.__inverse_indexed = {} for filename in os.listdir(directory): doc = Document(directory + '/' + filename) self.__allDocs.append(doc) for doc in self.__allDocs: for term in doc.get_words(): ifnot term in self.__inverse_indexed: self.__inverse_indexed[term] = [] self.__inverse_indexed[term].append(doc.get_path())
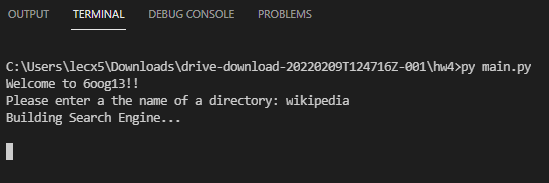 第一次建立時,由於需要針對整個文本庫進行分析,文本庫越大,花費的時間越久。
第一次建立時,由於需要針對整個文本庫進行分析,文本庫越大,花費的時間越久。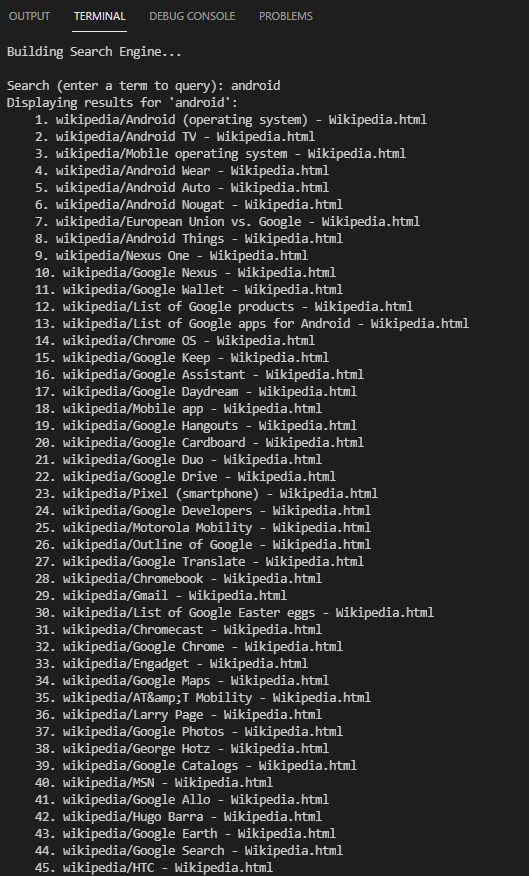 搜尋結果會依關聯性排序,且搜尋速度會非常快。
搜尋結果會依關聯性排序,且搜尋速度會非常快。